
Defining sustainability — Why so many mentions of carbon?
This is a six-part series on what sustainability means for the High Performance Computing Community. Post by Michael Rudgyard, CEO of Alces Flight.
What does it take to build a supercomputing solution that is designed for the long term? While the HPC community has historically procured its systems based on a narrow definition of the type of hardware to purchase, many of us are now concerned about the overall impact an HPC solution will have — not only on research, but also socially and ecologically.
Sustainable Pillars
The team at Alces recently set out to create an event which brought together some of the brightest minds and ideas in HPC. We then had to ask ourselves what sustainability actually means? While sustainability is most often associated with ecological impact, there are other factors to consider — and from our discussions we came to the conclusion that there are four key considerations, namely:
- The hardware, and where it is located.
- The software, and how it is optimised.
- The people, and how they are supported.
- Change, and how it is managed.
When taken together these ‘pillars’ currently provide the best foundation for building a long-term solution. So, how do you get started?
The Cost of Carbon
One of the first and biggest hurdles that people are confronted with is understanding their carbon footprint. So, what do we mean by carbon? And why is it found in every pillar of sustainability?
The term ‘carbon’ loosely refers to all greenhouse gas emissions (GHG), most often measured in Kg of CO2 equivalents, or KgCO2e. The carbon impact of an HPC system includes both ‘embedded carbon’ (the carbon used to manufacture, ship and eventually scrap or recycle hardware components) and the carbon that is used to power the system (including cooling and other related infrastructure within the host data centre). Rough estimates of the former may be given by the equipment manufacturers, while equally rough estimates of the latter may be obtained by monitoring power usage directly, as well as the ‘carbon intensity’ of power (the emissions related to the electricity supply and the mix between fossil fuel, low-carbon and renewable energy sources). Organisations increasingly have to report their approximate carbon footprint, and some even define a ‘carbon price’ (per KgCO2e) as a way of measuring the economic impact of their emissions. But with all that carbon, it’s hard to know where to start and where to end.
Fundamentally it is difficult for the HPC community to account for all of its carbon production or consumption. However, what we can do is measure what we know and take the first steps to reduce the overall impact of our HPC systems. In fact, some steps are surprisingly simple.
Location, location, location!
Probably the easiest way we can reduce our carbon footprint is to make a good choice as to where we put the hardware . For example, it is better to host this in a data centre where the power overheads due to cooling are low, rather than in an old, inefficient data centre. Even better if we can re-use waste heat, or take advantage of power that is generated from low-carbon or renewable resources. If the carbon-intensity of power generation is low enough, we can even make a case for extending the life of computing equipment, or even recycling old hardware so as to minimize embedded carbon.
In order to show just how the above factors can make a difference, let’s take the hardware configuration of an actual HPC system that Alces recently shipped. We can use approximate figures given by the server manufacturer to estimate embedded carbon and annualise this by assuming it has a useful life of, say, five years. We now look at hosting this system in an old datacentre in the UK with a Power Usage Effectiveness, or PUE, of 1.5 (where we need to use 1kW of cooling for every 2kW that is used by the actual HPC resource) and then estimate the power needed to run the system flat out. In a second scenario, we look at hosting the same system in a state-of-the-art data centre in the Nordics, which has a PUE of 1.1 and where 30% of the waste heat is re-used (eg. for district heating) — noting that by most carbon accounting measures, heat re-use has the effect of reducing the overall carbon impact. Finally, we compare a recycled five year-old system that is also housed in the same Nordic data centre, and we assume that the embedded carbon has already been accounted for. To make comparisons fairer, we also normalise the total annual carbon intensity by the GFlop rating of the HPC systems (using a rather synthetic benchmark), as shown in the graph below.
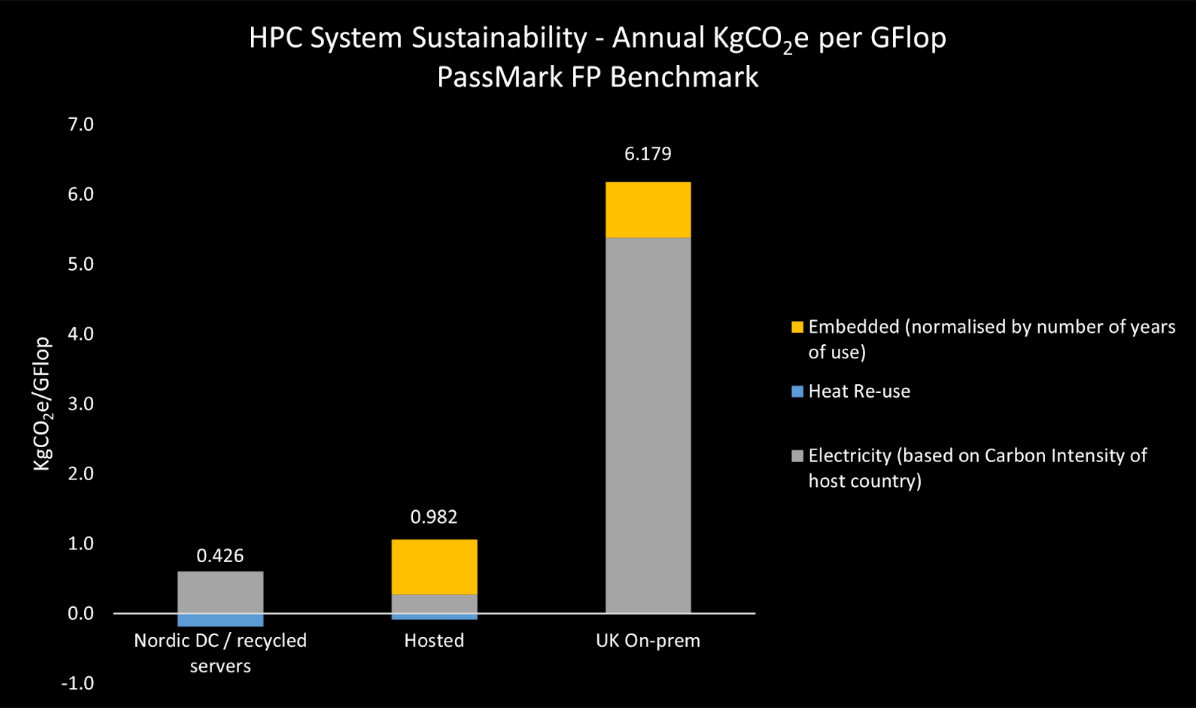
The conclusions are pretty striking, even if the data is inaccurate. Firstly, we see that a traditional UK data-centre is not the obvious choice for hosting a new HPC system, largely due to the carbon intensity of UK electricity supply. In comparison, the carbon intensity of energy supply in the Nordic countries is about 1/10th that of the UK, and infrastructure for district heating systems is more common, which is why we see an 84% reduction in the carbon impact in our example. Equally striking is the effectiveness of recycled hardware when it is hosted in an efficient Nordic data centre, with a 93% reduction in the carbon impact per GFlop.
While the focus here is on sustainability, the relative cost of electricity in the Nordics means that the economic case for re-locating new HPC systems is also striking, and extending the life of old hardware also becomes significantly more viable.
But before we write off the whole UK data centre sector on the basis of the carbon intensity of our national electricity supply, we need to consider other factors. Most forward-thinking data centres either off-set their emissions, sign-up to a “100% renewable” electricity supply, or go as far as entering into a Power Purchasing Agreement (PPA) — although often with a supplier that is located in a completely different geography, with no means of exporting their energy to the UK. The jury is out as to what extent this is ‘greenwashing’, as if nothing else it does encourage global investment in renewables. By 2030, Google Cloud is aiming to match 100% of its energy consumption with renewable energy purchases (on a 24/7 basis), which is arguably a much more transparent approach. Our UK data centre partner Deep Green is pursuing a strategy of heat re-use and on-site renewable energy production so as to be carbon negative while also minimizing costs for HPC users …but we shall hear more from them later in this blog series.
System utilization and application optimization
Things become slightly more murky when we consider the less tangible issuesof software optimisation, people and change management. Notionally, we now need some kind of metric that might describe the research outcomes per KgCO2e, although such a metric would be very difficult to define and measure. But as before, that doesn’t mean we can’t make meaningful changes and ask ourselves some important questions:
- How reliable is our system? Is the whole system functioning properly? We note that for many parallel applications, an intermittent problem with a single server or network connection can lead to a significant loss of valuable computing cycles. Similarly, misconfigured or unhealthy storage components can act as a throughput bottleneck.
- How are we training and supporting our users? Are we teaching best practices and helping to improve the research outcomes for projects that useour HPC resource? Are our users writing efficient code?
- Are we optimizing system throughput? Are we benchmarking for realistic performance? Are we tailoring our hardware or resources for maximum application efficiency? Are we ensuring that our users do not demand resources at a scale that their applications cannot effectively make use of?
- Are we updating and repurposing older systems, specifically targeting them at applications which cannot make good use of more modern processors?
It is especially important to note that wasted cycles equate to unnecessary cost and carbon emissions, so in some cases up-front investments in areas such as training and optimisation will pay large dividends down the road.
Want to know more?
We’re pleased to say Michael’s full talk is now available:
Next time…
In the next part of the sustainability series we will dive deeper into the ‘where’ factor of hosting our HPC resource. And by dive, we mean that actual swimming pools are involved — and not just for effect.